

نحوه ساخت مدل در یادگیری ماشین با یک مثال کاربردی
نویسنده : مهسا اذانی | تاریخ بروزرسانی : 1400/04/16
بیایید تصور کنیم در حال ساخت یک مدل یادگیری ماشین برای کشف تقلب برای یک کسب و کار سفارش آنلاین غذا هستیم. کسب و کار داستانی ما DeliverDinner نام دارد.
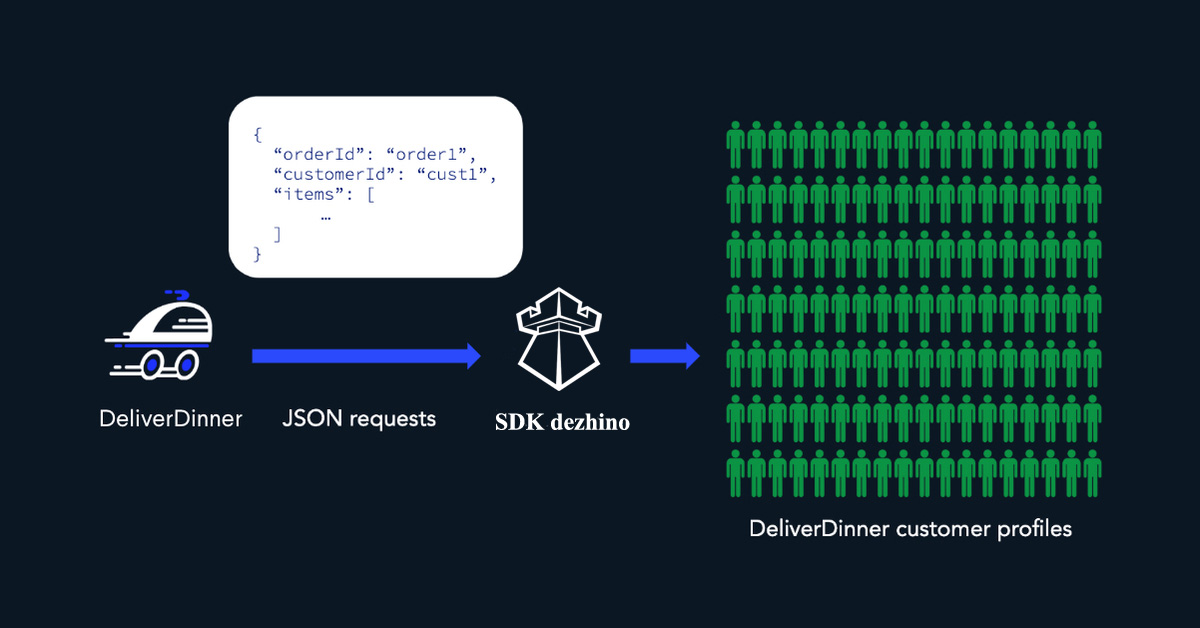
هنگامی که DeliverDinner به عنوان مشتری جدید به دژینو می پیوندد ، آنها شروع به ارسال ترافیک معاملات لحظه ای با SDK ما می کنند.
هر بار که مشتری وارد سایت می شود، در لندینگ پیج اقدامی انجام می دهد و هر کاری را در وب سایت DeliverDinner انجام می دهد، درخواست JSON را با SDK ارسال می کند. این بدان معنی است که ما داده های زیادی در مورد مشتریان DeliverDinner و همه کارهایی که آنها در حساب خود انجام داده اند ذخیره می کنیم. ما این موارد را در نمایه های مشتری بسته بندی می کنیم.
برای استفاده از این داده ها برای یادگیری ماشین باید سه کار انجام دهیم:
- برچسب زدن به مشتریان بر اساس با تقلب / بدون تقلب
- مشتریان را به زبان رایانه توصیف کنید
- مدل را آموزش دهید
مرحله 1: اختصاص برچسب ها
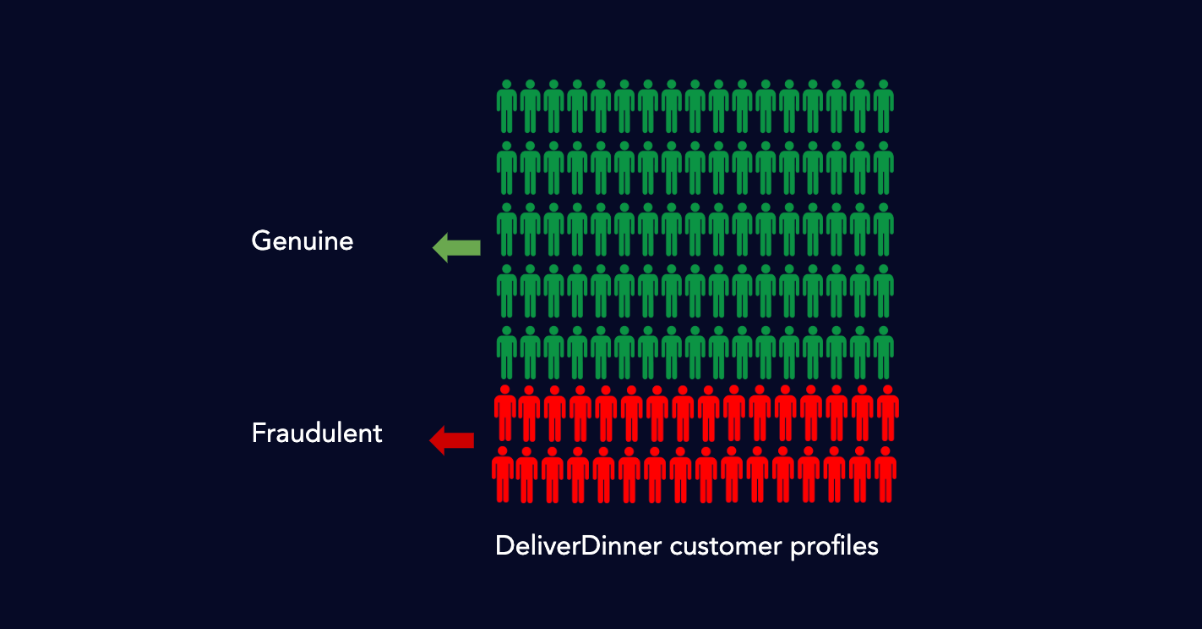
ما به هر مشتری که فعالیت نامتعرف(آنومالی) داشته یا به صورت دستی توسط دیتاساینس بررسی شده است، نگاه می کنیم و آنها را به عنوان تقلب برچسب می زنیم.
مرحله 2: ایجاد ویژگی ها
ایجاد ویژگی ها در اصل توصیف هر مشتری است به گونه ای که کامپیوتر بتواند آن را درک کند. ما می خواهیم خصوصیات مشتری را توصیف کنیم که نشان می دهد تقلب یا واقعی بودن آنها است، این بر اساس همان جنبه هایی است که یک تحلیلگر تقلب برای تصمیم گیری بررسی می کند.
نمونه هایی از ویژگی هایی که می تواند شاخص های خوبی برای تقلب باشد:
- نرخ سفارش: متقلبان با سرعت بسیار بیشتری سفارش می دهند، ما این تعداد را به تعداد سفارش در هفته تعیین می کنیم.
- ایمیل: ممکن است متقلب، ایمیلی با ظاهری ناخوشایند داشته باشد، ما ٪ آدرس ایمیل ها را بررسی می کنیم
- محل تحویل: ممکن است جایی واقعی باشد یا بعید است مانند یک آپارتمان پنت هاوس تقلب داشته باشد، یا ممکن است در جایی مانند پارک تقلبی باشد. ما به این % از میزان تقلب در مکان را اختصاص میدهیم. و مثال هایی بیشتر …
همه ویژگی ها به عنوان یک عدد ایجاد می شوند زیرا مدل نمی تواند متن خام را جذب کند. ما ویژگی های خود را ایجاد کرده و آنها را به گروه های مختلف دسته بندی می کنیم.
مرحله 3: مدل را آموزش می دهیم
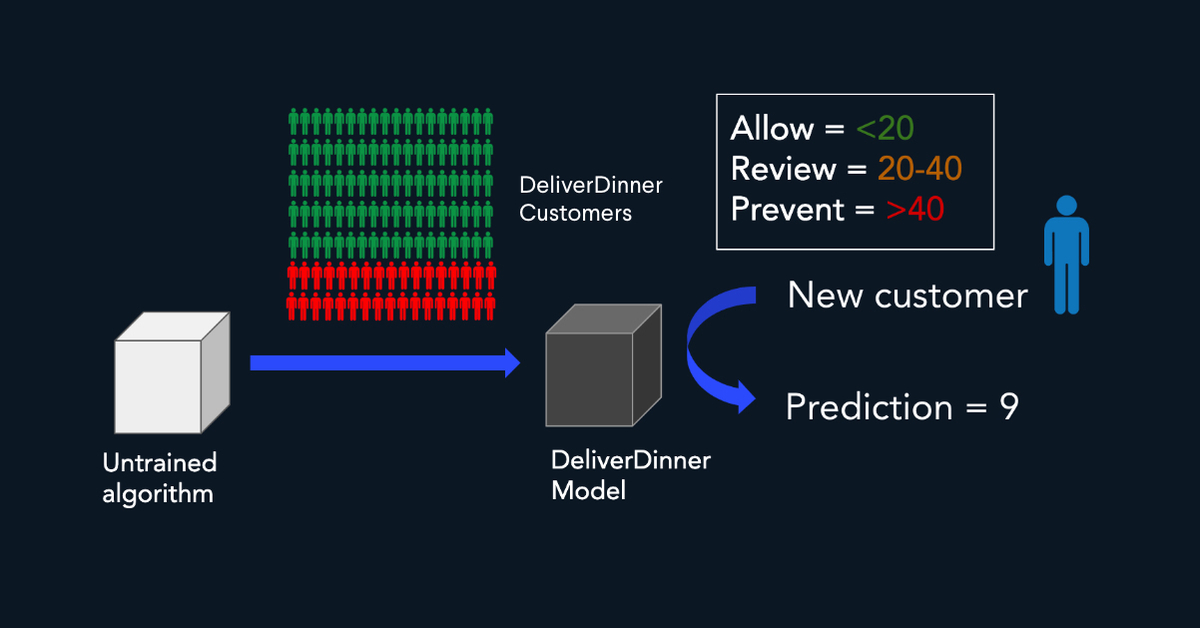
ما باید داده ها را به الگوریتم اضافه کنیم تا بتواند نحوه حل مسئله را بیاموزد. در این مرحله، ما اطلاعات یادگیری شده را اضافه می کنیم.
داده های یادگیری شده مجموعه ای از داده های DeliverDinner در مورد مشتریان است که از نظر ویژگی ها و برچسب های آنها شرح داده شده است تا الگوریتم را از تقلب یا مشتری واقعی مطلع سازد. این به مدل کمک می کند تا یاد بگیرد چگونه تفاوت بین واقعی یا تقلب را تشخیص دهد.
در مجموعه داده های DeliverDinner، این ممکن است نشان دهد که مشتریان واقعی تمایل دارند هر هفته یک بار سفارش دهند، آنها هر بار از کارت مشابه استفاده می کنند و آدرس صورتحساب + تحویل اغلب یکسان است. متقلبان ممکن است نشان دهند که آنها چندین بار در هفته سفارش می دهند، از کارتهای مختلف زیادی استفاده می کنند، کارتهایشان ثبت نام نکرده است و آدرس صورتحساب و تحویل اغلب با هم مطابقت ندارند.
این الگوریتم این ارزش را به خود می گیرد و روش بی نقصی را برای بررسی اینکه آیا ویژگی های مشتری بیشتر شبیه انبوه مشتری اصلی است یا توده مشتری متقلب، یاد می گیرد.
هنگامی که ما مشتری جدیدی را که قبلاً ندیده است به مدل نشان می دهیم، آن را با مشتریان واقعی / تقلبی که قبلاً دیده است مقایسه می کند و نمره تقلب تولید می کند. این امتیاز نشان دهنده احتمال تقلب مشتری جدید است.
برای اکثر مشتریان، نمره تقلب بسیار پایین خواهد بود، زیرا مشتریان واقعی بیشتر از تقلب وجود دارد. وقتی امتیاز کم است، توصیه می کنیم مشتری و معامله انجام شود. اگر نمره متوسط است، ما یک بررسی از معامله را توصیه می کنیم. ارسال مشتری به چالش امن 3D(ریکپچا یا حل پازل) برای احراز هویت. اگر امتیاز بسیار بالا است، توصیه می کنیم مشتری را در انجام معامله مسدود کنید.
چگونه محدودیتهای مجاز / بازبینی / جلوگیری از آنها را تصمیم می گیرید؟
تعیین حد مناسب برای آستانه های مجاز / بازبینی / جلوگیری از این امر به دقیق و یادآوری فراخوان بستگی دارد.
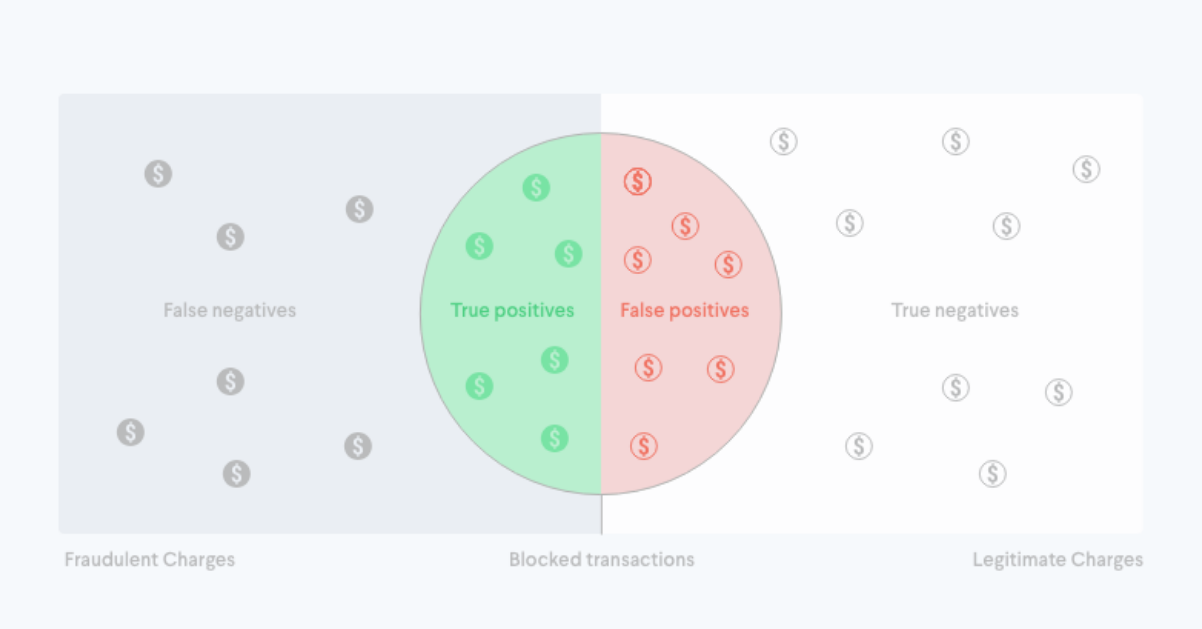
سوال دقیق: از کل مشتری های ممانعت شده، چه نسبتی متقلب بودند؟
سوال یادآوری: از همه متقلب ها ، از چه نسبتی جلوگیری کردیم؟
قرار دادن دقت و یادآوری در متن
اگر آستانه پیشگیری شما 95% باشد، درصد بسیار کمی از مشتریان را مسدود می کنید. دقت بسیار بالایی نخواهید داشت، فقط چند مشتری را که کاملاً مطمئن هستید متقلب هستند مسدود می کنید. میزان مثبت کاذب(مثبت کاذب را در این جا مطالعه کنید) بسیار کمی خواهید داشت. با این حال، به احتمال زیاد فراخوان کم باشد زیرا احتمالاً متقلبان با امتیازات زیر 95% وجود دارند که شما از آنها جلوگیری نمی کنید.
اگر آستانه پیشگیری شما 5% باشد. شما از تعداد زیادی از ترافیک خود جلوگیری می کنید و بنابراین احتمال دارد از دقت بسیار زیادی برخوردار باشید و احتمالاً در نهایت با بسیاری از موارد مثبت کاذب روبرو خواهید شد. شما فراخوان زیادی خواهید داشت، زیرا اگر بیشتر از متقلبان باشد ، بیشتر آنها را مسدود خواهید کرد.
تنظیم آستانه ریسک مناسب
این یک مقدار تعادل بین این دو است و اینکه شما آستانه های خود را تعیین کنید به اولویت های کاری فردی شما بستگی دارد. به راحتی می توانید این موارد را تغییر دهید بسته به ریسک پذیری شما دارد اگر بیشتر نگران تقلب یا مثبت کاذب هستید.
درک دقیق، یادآوری و تعیین آستانه های خطر برای ما مهم است تا درک کنیم چگونه می توانیم صحت مدل خود را ارزیابی کنیم و از بهبود آن اطمینان حاصل کنیم.
بنابراین ما می دانیم که چگونه یک مدل را می سازیم، اما چگونه تصمیم می گیریم که چه داده هایی را بررسی کند؟
نتیجه گیری
پیشنهاد ما در دژینو تعیین آستانه با ریسک مناسب است، چون هم نمی خواهیم مثبت کاذب زیادی و هم اینکه تقلب زیادی داشته باشید.
برای اطلاعات بیشتر لطفاً با ما در ارتباط باشید.