

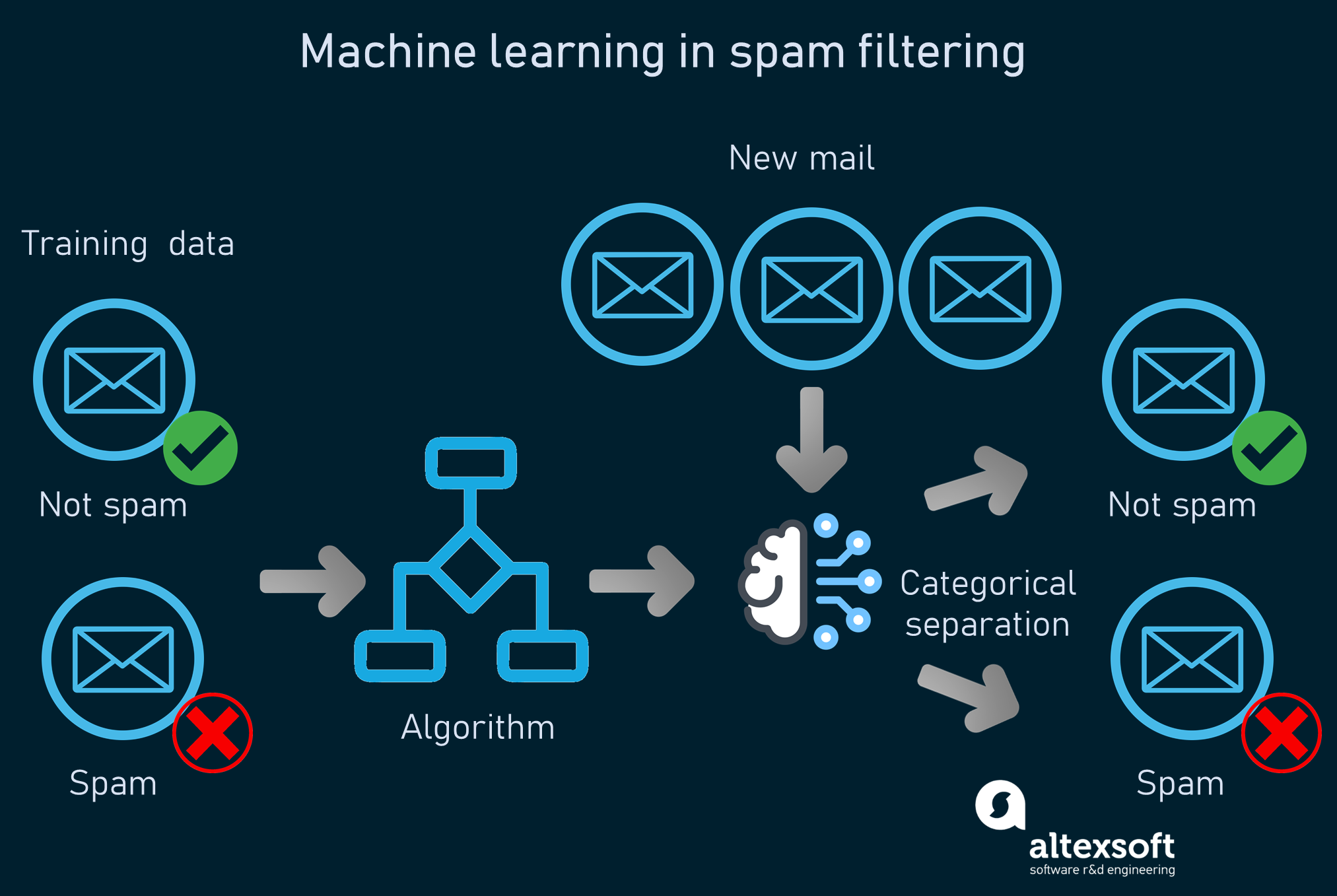
چه داده هایی را در یادگیری ماشین استفاده می کنیم؟
نویسنده : مهسا اذانی | تاریخ بروزرسانی : 1400/03/21
تصمیم داریم در مورد این صحبت کنیم که چه داده هایی را برای یک مدل یادگیری ماشین استفاده می کنیم و چگونه داده های مناسب یک کسب و کار را برای مهندسی ویژگی انتخاب می کنیم.
هر کسب و کاری داده های زیادی دارد، اما همه آنها مربوط به تقلب نیستند. در اینجا نحوه انتخاب ویژگی های خاص داده ها برای تجزیه و تحلیل و دریافت نشانه ای از تقلب وجود دارد.
اول اینکه ویژگی چیست و چگونه مهندسی می شود؟
در یک سطح اساسی، یک ویژگی یک مشخصه قابل اندازه گیری منحصر به فرد دارد یا همان خصوصیات است، مانند هزینه یک معامله. مهندسی ویژگی، فرآیند استخراج این خصوصیات معنی دار است که از آن به عنوان ماده یادگیری الگوریتم استفاده می شود.
ساختار ویژگی ها
ما به دنبال ویژگی هایی برای گرفتن جنبه های خاص هستیم که به ما در پیش بینی تقلب کمک می کند. ما انواع ویژگی ها را در دسته های زیر گروه بندی می کنیم.

ویژگی های سنتی
این جنبه های معمول پیش بینی تقلب است، به عنوان مثال سفارشات، معاملات، کارت ها، مکان، ایمیل. این ویژگی ها عموماً داده هایی را که انتظار داریم را پوشش می دهد.

ویژگی های رفتاری
ما ویژگی های رفتاری را از سشن مشتری می گیریم. این ویژگی ها بر اساس تعریف اقدامات مشتری است، به عنوان مثال: سرعت سفارشات، زمان صرف شده در صفحه، مدت زمان بین افزودن کارت جدید و سفارش. یکی از اهداف استخراج این ویژگی ها، به کار بردن سایر موارد استفاده از فناوری خرابکارانه است. اگر یک متقلب از اسکریپتی برای اخلال یک صفحه وب در مقابل فعالیت مرور طبیعی استفاده می کند.

ویژگی های زمان واقعی
ویژگی های زمان واقعی بر اساس بروز تقلب در دنیای واقعی است. این ویژگی ها همه براساس داده های طبقه بندی شده است. نرخ تقلب را در زمان واقعی براساس گروه ها ارائه می شود. کشور / ارقام کارت ASN / دامنه ایمیل و غیره. یکی از ویژگی های نمونه می تواند میزان تقلب در برخی مناطق/کشورها باشد.
یکی از اهداف این ویژگی ها کمک به کسب و کار ها برای گسترش در بازارهای جدید است که هیچ داده وجود ندارند. ما ترافیک را به صورت لحظه ای کنترل می کنیم تا به کسب و کار های خود کمک کنیم بدون درز از طریق مدل های یادگیری ماشین به بازارهای جدید منتقل شوند.

ویژگی های فردی مشتری
این ویژگی ها در مورد شباهت رفتار معمول مشتری خاص که در گذشته اتفاق افتاده است به ما می گوید. این می تواند هزینه معمول آنها، آدرس صورتحساب عادی، آدرس IP خانه و غیره باشد.

ویژگی های تِرَک کردن سشن
این ویژگی ها کمی بیشتر از ویژگی های رفتاری دخیل هستند. این ویژگی ها داده هایی را که مثلاً از Javascript به دست می آوریم پوشش می دهد. اینکه آیا مشتری شماره کارت را در صندوق قرار می دهد، کوکی ها اگر از رمز عبور استفاده می کنند و غیره. یکی از اهداف این ویژگی ها گرفتن رفتار مشتری واقعی است.

ویژگی های نهادی
ما ویژگی ها را به مشتری محور و نهاد محور تقسیم می کنیم. نهادی ها مواردی مانند دستگاه ها، آدرس ها، مکان ها، دامنه ها و ایمیل ها هستند. به عنوان مثال تعداد سفارشات ارسال شده به آدرس خاص است. یکی از اهداف این ویژگی ها هشدار دادن به ما برای وجود تقلب است.

ویژگی های مشتق شده از شبکه
علاوه بر ویژگی های مشتری مدار و نهاد محور، ما همچنین به دنبال ویژگی های سطح شبکه هستیم. این ویژگی ها بر توپولوژی شبکه (شکل شبکه) به عنوان ابزاری برای افزایش اطلاعات مشتری ما متمرکز هستند. به عنوان مثال اشتراک یک اکانت بین خانواده یک خانه در مقابل آن در یک شبکه صدها حساب از تعداد کمی دستگاه مشابه استفاده می کنند.