

سه مورد از پر کاربردترین مدل های یادگیری ماشین
نویسنده : مهسا اذانی | تاریخ بروزرسانی : 1400/03/21
ما برای دستیابی به بهترین عملکرد از ترکیبی از معماری های مدل مختلف استفاده می کنیم، در اینجا معرفی مختصری از سه معماری برجسته ای است که ما استفاده می کنیم و اینکه چرا از آنها استفاده می کنیم توضیح خواهیم داد با ما همراه باشید.
از آنجا که هر کسب و کار منحصر به فرد است، ما برای هر یک میکرو مدل های جداگانه آموزش می دهیم و داده جمع می کنیم. این منجر به این می شود که هر مشتری راه حلی مناسب با داده های خاص خود و روند تقلب داشته باشد.
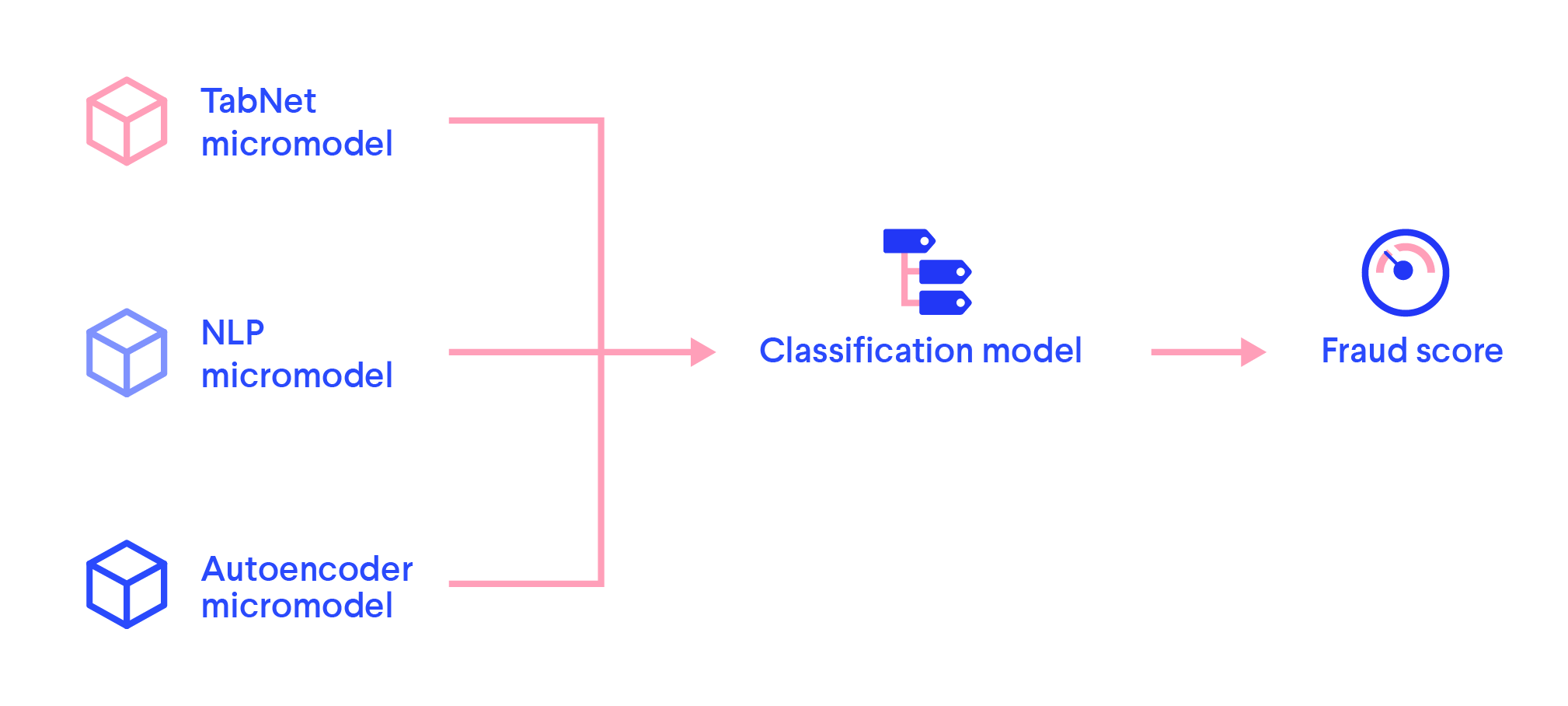
این راه حل از یک معماری میکرو مدل تشکیل شده است، به این معنی که ترکیبی از مدل های مختلف برای داده های مختلف در یک نوع است. هر یک از مشاغل جداگانه بسته به داده های خود، وزن متفاوتی را در مدل های مختلف دارند.
این مدل های منحصرا اختصاصی بهترین نمایش قسمت های مشخصی از پایگاه داده را یادگیری می کنند. در اینجا یک نمایش ساده از این وجود دارد:
ما از سه میکرو مدل خبره استفاده می کنیم
سه معماری برجسته میکرو مدلی که ما استفاده می کنیم:
- tabnet
- پردازش زبان طبیعی (NLP)
- خود رمزگذارهای تشخیص ناهنجاری
علاوه بر این سه مدل ، ما از انواع متخصصان گوناگون برای ساختن مدل “مخلوطی از متخصصان” استفاده می کنیم. هر یک از مدل ها در نوع خود خبره است، ما سه مورد فوق را با جزئیات بیشتری توضیح خواهیم داد.
1-میکرو مدل TabNet
برای معرفی مدل معماری TabNet، بهتر است که ابتدا به معماری جنگل تصادفی معروف تر نگاه کنیم.
جنگل تصادفی و درختان تصمیم
یک معماری تصادفی جنگل از بسیاری از درختان تصمیم گیری تشکیل شده است، ابتدا ببینیم درخت تصمیم چیست؟
درخت تصمیم مجموعه ای از سوالات با پاسخهای بله / خیر است که هدف آن تقسیم داده ها به طبقات مختلف است. هدف این است که درخت داده ها را به گروههایی که ممکن است با یکدیگر متفاوت باشند تقسیم کند و اعضای هر گروه نیز تا حد امکان به یکدیگر شباهت داشته باشند.

جنگل تصادفی مجموعه ای از درختان تصمیم گیری است که در سطح طبقه بندی مخلوط می شوند.
مزایای کشف تقلب
از معماری تصادفی جنگل قبلاً معمولاً در کشف تقلب استفاده می شود. مزایای این معماری عبارتند از:
- استقرار سریع
- چندین درخت تمایل به یک طرف کلی را کاهش می دهد
- تفسیر و درک عملکردهای داخلی آسان است
- الگوریتم پایدار که با افزودن پایگاه داده جدید اختلال ایجاد نمی شود
معایب برای کشف تقلب
جنگل تصادفی در سطح طبقه بندی مخلوط شده است، نه در سطح نمایندگی. این بدان معنی است که مدل طبقه بندی نمی داند کدام درختان در تصمیم گیری وزن کمتری دارند، که این امر قدرت پیش بینی کمتری به آن می دهد.
یک مشکل در جنگل تصادفی این است که می تواند مستعد استفاده از تجهیزات بیش از حد باشد. مجهز بودن بیش از حد زمانی ایجاد می شود که مدل یا الگوریتم به خوبی با داده های آموزش متناسب باشد. داده ها را به بیش از حد کلاسهای مجزا تقسیم می کند.
این بدان معنی است که درمورد انجام آموزشهای خاص نسبت به انجام کلاس بندی کلی تر که می تواند در مورد بسیاری از مشتریان اعمال شود، چیزهای زیادی را یاد می گیرد این می تواند منجر به عملکرد ضعیف در محیط زندگی برای مشتریان شود که در مجموعه داده های آموزشی نیستند.
چرا TabNet یک پیشرفت است؟
TabNet برای توضیح پذیری عالی است و به ما اجازه می دهد تا بفهمیم کدام ویژگی ها بیشترین وزن را در پیش بینی دارند و تجزیه و تحلیل بیشتر را نیز ممکن می کند، برخلاف جنگل تصادفی.
هدف از این میکرو مدل برای دژینو یادگیری موارد زیر است:
- داده های عددی
- ویژگی های طبقه ای اصالت کم (ویژگی هایی با تعداد کم دسته، به عنوان مثال قاره ها به جای کشورها)
نتایج TabNet در یک مدل با کارایی بالا است که از سایر شبکه های عصبی و انواع درخت تصمیم بهتر عمل می کند. چه چیزی آن را بسیار کارآمد می کند؟
طراحی مدل Tabnet

بیش از بله / خیر
تفاوت کلیدی دیگر با TabNet این است که فقط یک تصمیم و پاسخ بله / خیر نیست. به جای طبقه بندی ساده داده ها در کلاسهای درست / غلط در هر مرحله، مدل می تواند طبق یک مقدار طبقه بندی کند. مقدار تراکنش. در زیر دو عنصر اصلی وجود دارد.
تبدیل کننده با دقت توجه مدل را معطوف می کند. این یک روش قدرتمند برای اولویت بندی ویژگی های مورد بررسی برای هر “مرحله تصمیم گیری” است. تبدیل کننده با دقت ممکن است در هر مرحله درباره صدها ویژگی مختلف سوال کنند. این همچنین دارای حافظه بلند مدت است و نتیجه مراحل قبلی تصمیم گیری و داده های واقعی تصمیم گیری ها را به یاد می آورد.
تبدیل کننده ویژگی ها تمام ویژگی های ارزیابی شده را بررسی می کند و تصمیم می گیرد که کدام یک از رفتارهای تقلبی / واقعی را نشان می دهد. تبدیل کننده ویژگی دارای فرایندهای تصمیم گیری داخلی در معماری آن است.
محدودیت بیش از حد معماری
معماری TabNet می تواند از مشکلات بیش از حد که در جنگل های تصادفی رخ می دهد جلوگیری کند. این کار را به دو روش انجام می دهد: از طریق عملکرد از دست دادن و از طریق تبدیل کننده ویژگی.
ما می توانیم دانه دانه بودن مدل را محدود کنیم بنابراین آن ویژگی های تکراری تقلب را می آموزد تا ویژگی های یکتا یک معامله کلاهبرداری یاد بگیرد. این مدل کلی تر است بنابراین می تواند داده های جدیدی را پیش بینی کند که با آنچه قبلاً دیده شده یکسان به نظر نرسد.
تبدیل کننده ویژگی بر فرایندهای تصمیم گیری قابل استفاده مجدد تأکید دارد و به عبارت دیگر نحوه تصمیم گیری را “به یاد می آورد”. این بدان معناست که اگر تبدیل کننده ویژگی بیش از یک بار داده های مشخصه یکسانی را ببیند، سعی خواهد کرد هر بار به همان روش تصمیم بگیرد و جلوگیری از دانه دانه شدن بیشتر در زنجیره تصمیم گیری است.
2- میکرو مدل پردازش زبان طبیعی (NLP)
مدل های NLP(Natural language processing) اغلب در برنامه هایی مانند تشخیص صدا، فیلترهای هرزنامه ایمیل یا خدمات ترجمه استفاده می شوند.
در دژینو، هدف مدل NLP ارزیابی ویژگی های متنی مانند ایمیل، محتوای سبد سفارش، یادداشت های تحویل و سایر موارد متنی است.
طراحی مدل NLP
نمونه ای از معماری NLP برای سبد سفارش تحویل غذا می تواند به صورت زیر باشد:

توکن سازی / لایه گذاری این است که چگونه متن را به اعدادی تبدیل می کنیم که مدل بتواند آنها را به عنوان داده درک کند. در مدل ما برای افزایش انعطاف پذیری مدل نسبت به موارد جدید و همچنین ویژگی های جدید، در سطح کاراکترها رمزگذاری می کنیم.
این بدان معنی است که یافتن تکرار در داده ها آسان تر است و به عنوان مثال تکرار رشته ای از نامه های تصادفی در آدرس های ایمیل تقلبی با تغییرات فزاینده است.
جاسازی و مورد BiLSTM – موارد به صورت جداگانه جاسازی می شوند و از طریق یک بلوک حافظه کوتاه مدت بلند مدت دو طرفه (biLSTM) منتقل می شوند تا مدل را به یادگیری موارد مشابه ترغیب کنید. لاته و کاپوچینو. در سطح مورد، LSTM زمینه اضافی را به متن اضافه می کند، متن را در صورت لزوم گروه بندی می کند. به عنوان مثال، ممکن است “سیاه” با “قهوه” و “چای” با “شیر” گروه شود.
سفارش BiLSTM – سفارش نهایی biLSTM سبدهای سفارش معمول را یاد می گیرد مثلا ماده غذایی و یک نوشیدنی. داشتن LSTM دو طرفه به این معنی است که ترتیب زمانی تأثیر نامطلوبی ندارد. اگر کسی ابتدا نوشیدنی و سپس غذا یا غذا و سپس نوشیدنی بخورد، بر حالت تأثیر منفی نمی گذارد. این امر همچنین یادگیری سفارشات و سایر رفتارهای کاربر را ارتقا می بخشد.
مزایای استفاده از معماری NLP ما
NLP می تواند عنصر تعصب انسانی را که در ساخت ویژگی های متن وجود دارد حذف کند و به عنوان مثال یک انگلیسی زبان ممکن است فقط با متن انگلیسی آشنا باشد و ویژگی ها را بر اساس دانش خود و قوانین زبان انگلیسی ایجاد کند. NLP می تواند زبانهای مختلف و بدون سربار منابع انسانی را شامل شود و این نوع تمایل داشتن به یک طرف را کاهش دهد.
با استخراج متعارف ویژگی متن، یک ویژگی جدید یا یک قسمت متن جدید به شخص نیاز دارد تا این ویژگی را به صورت دستی در مدل ایجاد کند. NLP این کار را به صورت خودکار انجام می دهد و در هنگام معرفی محصولات جدید، دامنه های ایمیل و غیره از بار انسانی می کاهد.
3-مدل تشخیص ناهنجاری
معماری دیگری که ما از آن استفاده می کنیم یک مدل مخلوط خودکار رمزگذاری عمیق گوسی (DAGMM) است. این مدل داده ها را متراکم می کند و نمایشی فشرده را یاد می گیرد و به آن اجازه می دهد مشتریان جدید را به عنوان نمونه مجموعه داده موجود تأیید کند یا موارد پرت را شناسایی کند.
این نوع مدل ها گاهی اوقات در فشرده سازی تصویر مانند پخش زنده ورزش / فیلم استفاده می شود. اگر جریان بی کیفیت باشد و پیکسل ها از بین بروند ، مدل می تواند سعی کند تصویر را از نمایش آموخته شده بسازد.

در گره های آبی، مدل سوالاتی را برای فشرده سازی داده ها می پرسد، سپس در سمت دیگر باید سوالات را برعکس بپرسد تا داده ها به همان شکل بیرون بیایند. این مدل سعی خواهد کرد سیگنالهای کلیدی در اطلاعات مشتری را تقطیر کند.
مدل تشخیص ناهنجاری تمام داده ها را شبیه سازی می کند و بر اساس ترکیبی از همه ویژگی ها، تصمیم می گیرد که آیا باید معامله را مجاز یا جلوگیری کند. ما برای اطمینان از انعکاس داده های فعلی، به طور مداوم مدل رفتار غیر عادی را به روز می کنیم.
هدف این مدل طبقه بندی رفتارهای جدید و غیر عادی کاربر است. این سوال را می پرسد که “آیا این مشتری جدید با مشخصات مشتری معمول مجموعه داده من سازگار است؟”
اگر جواب منفی باشد لزوماً به معنی تقلب مشتری نیست. این به عنوان سیگنالی تفسیر می شود که به مدل طبقه بندی (همراه با سایر نتایج مدل) منتقل می شود و قبل از دادن نمره تقلب به مشتری ، مخلوط می شود.
ترکیب مدل ها
همانطور که در بالا ذکر شد ، این سه معماری اصلی ما هستند اما ما از مدل های دیگری نیز در بالای این مدل ها استفاده می کنیم. هر مدل سیگنال هایی را به مدل طبقه بندی ارائه می دهد، و این ها قبل از تولید نمره نهایی مخلوط می شوند. یک مدل به تنهایی نمی تواند یک تصمیم کلی بگیرد، این فقط توسط مدل طبقه بندی انجام می شود. مدل طبقه بندی از یک ساختار شبکه عصبی ساده برای ارزیابی تمام سیگنالهای مدلهای مختلف استفاده می کند.
درک نتایج و جستجوی داخل جعبه سیاه
یادگیری ماشینی غالباً جعبه سیاه نامیده می شود زیرا شما واقعاً نمی توانید نحوه انجام کار خود را بررسی کنید.

یادگیری ماشینی و جعبه سیاه
اگرچه بازرسی از هر کاری که مدل انجام می دهد دشوار است، اما می توانیم از طریق آزمایش علت و معلومات، از نحوه کارکرد آن آگاهی پیدا کنیم. ما در داده هایی که در مدل تغذیه می کنیم تغییرات ظریف و کنترل شده ای ایجاد می کنیم و خروجی را اندازه می گیریم تا بتوانیم بگوییم که مدل هنگام پیش بینی چه داده هایی را پسندیده است، آیا آدرس های ایمیل مشکوک یا مقادیر بالای معامله را در اولویت قرار داده است. پیش بینی هر مشتری بلافاصله در داشبورد به طور کامل توضیح داده می شود.
چگونه بینش انسان مکمل یادگیری ماشین است
وقتی با موفقیت استفاده می شود، یادگیری ماشینی بار سنگین تجزیه و تحلیل داده ها را از تیم تشخیص تقلب شما برطرف می کند. نتایج به تیم در تحقیق، بینش و گزارش کمک می کند.
یادگیری ماشینی جایگزین تیم تحلیلگر تقلب نیست، اما به آنها این توانایی را می دهد تا زمان صرف شده برای بررسی دستی و تجزیه و تحلیل داده ها را کاهش دهند. این بدان معناست که تحلیلگران می توانند در موارد فوری متمرکز شوند و هشدارها را با دقت بیشتری ارزیابی کنند و همچنین تعداد مشتریان اصلی را که کاهش یافته اند کاهش دهند.
یادگیری ماشینی نقش یک تحلیلگر تقلب را کارآمدتر می کند، زیرا وقت آنها برای انجام کارهای استراتژیک بیشتر می شود. تحلیلگران از طریق بازبینی و برچسب زدن به مشتریان و تنظیم قوانین، سیستم های تشخیص تقلب در یادگیری ماشین را بهبود و بهینه می کنند. ماشین آلات در انجام کارهای سنگین در تجزیه و تحلیل داده ها، خرد کردن تعداد و خروجی بسیار خوب عمل می کنند. آنها شبانه خستگی ناپذیر کار می کنند و هرگز از آخر هفته های کاری شاکی نیستند.
ماشین آلات کمتر در مقابله با عدم اطمینان عمل می کنند. مواردی وجود دارد که جدید است، یا دشوار است، یا به نوعی متفاوت است. موارد لبه مواردی هستند که نیاز به توجه بیشتری دارند و ممکن است تعیین دشوار باشد و در اینجاست که بینش انسان وارد می شود و ارزش عظیمی را فراهم می کند.
مداخله متخصص انسان در اینجا فقط در مرحله تایید یک معامله نیست. این بیشتر موردی برای تجزیه و تحلیل بعد از رویداد و برچسب گذاری داده ها به شکلی است که به سرعت به ماشین بازخورد می دهد. به یاد داشته باشید، داده های دارای برچسب مجموعه نهایی آموزش برای یک ماشین است. بنابراین هرچه برچسب های رفتاری تأیید شده تری بتواند نتیجه دقیق تری نیز به دست آورد.
در حین وقایع تقلب زنده تحلیلگران تقلب می توانند با استفاده از بررسی های دستی، از وقوع حمله به ما اطلاع دهند. بینش انسان برای جلوگیری از حملات تقلب و محدود کردن تأثیر منفی کلیدی است.